

How a basic search engine algorithm works explained without math
This article is written for beginners who want to understand how search algorithm works.
I am going to write about how Google’s search algorithm (PageRank) worked when it launched in 1998 without writing any codes or technical terms. So that it’s easier to understand.
This algorithm was so superior at that time that, although it launched four years after the first commercial search engine and already popular Lycos and AltaVista, it outperformed all of them in terms of search quality.
The Hyperlink Trick
You already know what a hyperlink is : it is a link on a web page that takes you to another web page when you click on it.
Hyperlinks are one of the most important tools used by search engines to perform ranking, and they are fundamental to Google’s PageRank technology. The first step in understanding PageRank is a simple idea we’ll call the hyperlink trick. This trick is most easily explained by an example.
Suppose you are interested in learning how to make scrambled eggs and you do a web search on that topic.
Now any real web search on scrambled eggs turns up millions of hits, but to keep things really simple, let’s imagine that only two pages come up -

Search results for scrambled eggs
one called “Ernie’s scrambled egg recipe” and the other called “Bert’s scrambled egg recipe.”
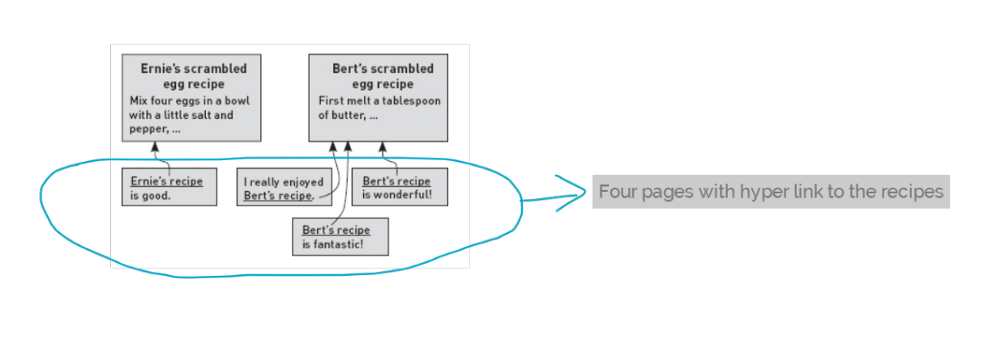
Pages with hyperlink to recipes
Also imagine that there are four pages on the entire web that link to either of our two scrambled egg recipes. So there are total four hyperlinks for these two recipes.
The question is, which of the two hits should be ranked higher, Bert’s recipe or Ernie’s?
As humans, it’s not much trouble for us to read the pages that link to the two recipes and make a judgment call. But computers are not good at understanding what a web page actually means. So they can’t rank it like how a human ranks a web page.
On the other hand, computers are excellent at counting things. So one simple approach is to simply count the number of pages that link to each of the recipes - in this case, one for Ernie, and three for Bert - and rank the recipes according to how many incoming links they have.
Of course, this approach is not nearly as accurate as having a human read all the pages and determine a ranking manually, but it is nevertheless a useful technique.
It turns out that, if you have no other information, the number of incoming links that a web page has can be a helpful indicator of how useful, or “authoritative,” the page is likely to be.
In this case, the score is Bert 3, Ernie 1, so Bert’s page gets ranked above Ernie’s when the search engine’s results are presented to the user.
You can probably already see some problems with this “hyperlink trick” for ranking. One obvious issue is that sometimes links are used to indicate bad pages rather than good ones. For example, imagine a web page that linked to Ernie’s recipe by saying, “I tried Ernie’s recipe , and it was awful.” Links like this one, that criticize a page rather than recommend it, do indeed cause the hyperlink trick to rank pages more highly than they deserve. But it turns out that, in practice, hyperlinks are more often recommendations than criticisms, so the hyperlink trick remains useful despite this obvious flaw.
The Authority Trick
You may already be wondering why all the incoming links to a page should be treated equally.
Surely a recommendation from an expert is worth more than one from a novice? To understand this in detail, we will stick with the scrambled eggs example from before, but with a different set of incoming links.
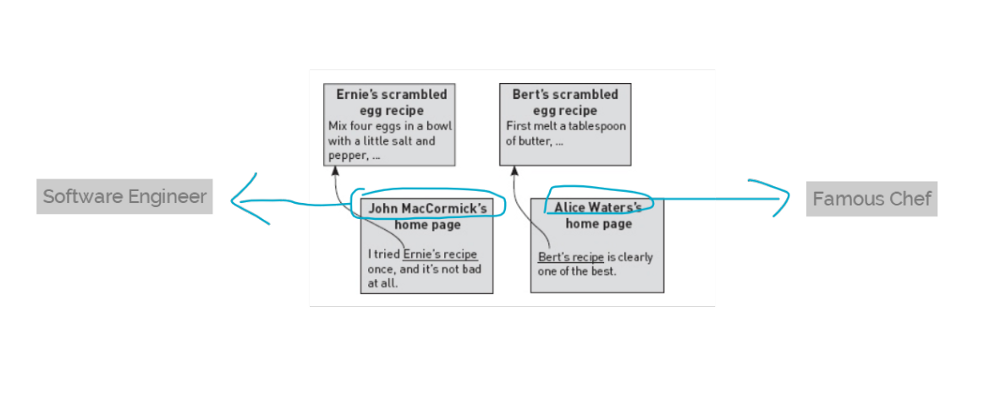
Recipes got different authoritative incoming links
The figure shows the new setup: Bert and Ernie each now have the same number of incoming links/hyperlinks (just one), but Ernie’s incoming link is from a software engineer, whereas Bert’s is from the famous chef Alice Waters.
So, whose recipe would you prefer?
Obviously, it’s better to choose the one recommended by a famous chef, rather than the one recommended by a software engineer.
This basic principle is what we’ll call the “authority trick”: links from pages with high “authority” should result in a higher ranking than links from pages with low authority.
This principle is all well and good, but in its present form it is useless to search engines. How can a computer automatically determine that Alice Waters is a greater authority on scrambled eggs than an engineer?
Here is an idea that might help: let’s combine the hyperlink trick with the authority trick. All pages start off with an authority score of 1, but if a page has some incoming links, its authority is calculated by adding up the authority of all the pages that point to it. In other words, if pages X and Y link to page Z, then the authority of Z is just the authority of X plus the authority of Y.
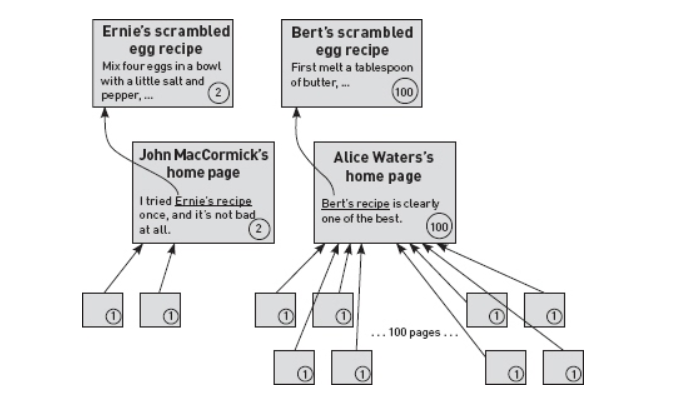
Calculation of authority scores for the two recipes
The figure gives a detailed example, calculating authority scores for the two scrambled egg recipes. The final scores are shown in circles.
- There are two pages that link to John’s home page; these pages have no incoming links themselves, so they get scores of 1. John’s page gets the total score of all its incoming links, which adds up to 2.
- Alice Waters’s home page has 100 incoming links that each have a score of 1, so she gets a score of 100.
Ernie’s recipe has only one incoming link, but it is from a page with a score of 2, so by adding up all the incoming scores (in this case there is only one number to add), Ernie gets a score of 2.
Bert’s recipe also has only one incoming link, valued at 100, so Bert’s final score is 100. And because 100 is greater than 2, Bert’s page gets ranked above Ernie’s.
The Random Surfer Trick
It seems like we have hit on a strategy for automatically calculating authority scores that really works, without any need for a computer to actually understand the content of a page. Unfortunately, there can be a major problem with the approach. It is quite possible for hyperlinks to form what computer scientists call a “cycle.” So if we can solve this problem, we have our search algorithm !
A cycle exists if you can get back to your starting point just by clicking on hyperlinks.
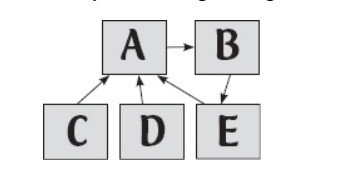
An example of cycle
There are 5 web pages labeled A, B, C , D, and E. If we start at A, we can click through from A to B, and then from B to E - and from E we can click through to A , which is where we started. This means that A, B , and E form a cycle.
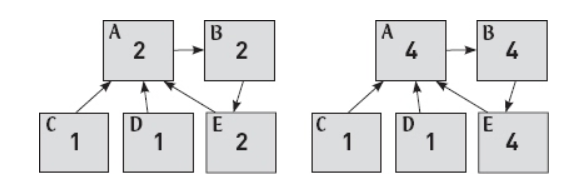
The problems with cycle
It turns out that our current definition of “authority score” (combining the hyperlink trick and the authority trick) gets into big trouble whenever there is a cycle. Let’s see what happens on this particular example. Pages C and D have no incoming links, so they get a score of 1. C and D both link to A, so A gets the sum of C and D, which is 1 + 1 = 2. Then B gets the score 2 from A, and E gets 2 from B. (The situation so far is summarized by the left-hand panel of the figure above.) But now A is out of date: it still gets 1 each from C and D, but it also gets 2 from E, for a total of 4. But now B is out of date: it gets 4 from A. But then E needs updating, so it gets 4 from B. (Now we are at the right-hand panel of the figure above.) And so on: now A is 6, so B is 6, so E is 6, so A is 8,…. You get the idea, right?
Calculating authority scores this way creates a chicken-and-egg problem. If we knew the true authority score for A, we could compute the authority scores for B and E. And if we knew the true scores for B and E , we could compute the score for A. But because each depends on the other, it seems as if this would be impossible.
Fortunately, we can solve this chicken-and-egg problem using a technique we’ll call the random surfer trick. Beware: the initial description of the random surfer trick bears no resemblance to the hyperlink and authority tricks discussed so far.
Random surfer trick combines the desirable features of the hyperlink and authority tricks, but works even when cycles of hyperlinks are present.
I am going to make it brief here and just cover the basics of random surfer mechanics.
The trick begins by imagining a person who is randomly surfing the internet. To be specific, our surfer starts off at a single web page selected at random from the entire World Wide Web.
The surfer then examines all the hyperlinks on the page, picks one of them at random, and clicks on it. The new page is then examined and one of its hyperlinks is chosen at random. This process continues, with each new page being selected randomly by clicking a hyperlink on the previous page.
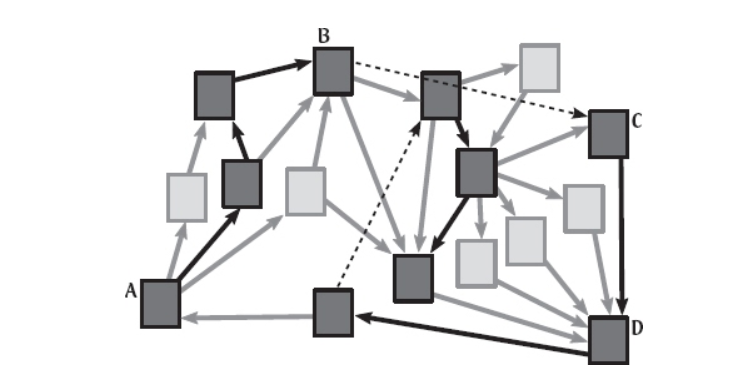
Imagining the entire World Wide Web consists of just 16 web pages
The figure above shows an example, in which we imagine that the entire World Wide Web consists of just 16 web pages.
Boxes represent the web pages, and arrows represent hyperlinks between the pages. Four of the pages are labeled for easy reference later.
Web pages visited by the surfer are darkly shaded, hyperlinks clicked by the surfer are colored black, and the dashed arrows represent random restarts, which are described next.
There is one twist in the process: every time a page is visited, there is some fixed restart probability (say, 15%) that the surfer does not click on one of the available hyperlinks. Instead, he or she restarts the procedure by picking another page randomly from the whole web.
It might help to think of the surfer having a 15% chance of getting bored by any given page, causing him or her to follow a new chain of links instead. To see some examples, take a closer look at the figure above. This particular surfer started at page A and followed three random hyperlinks before getting bored by page B and restarting on page C. Two more random hyperlinks were followed before the next restart.
(By the way, the random surfer example use a restart probability of 15%, which is the same value used by Google cofounders Page and Brin in the original paper describing their search engine prototype.)
So how random surfer model solves the problem with ranking pages ?
- First, we had the hyperlink trick: the main idea here was that a page with many incoming links should receive a high ranking. This is also true in the random surfer model, because a page with many incoming link has many chances to be visited.
- Second, we had the authority trick. The main idea was that an incoming link from a highly authoritative page should improve a page’s ranking more than an incoming link from a less authoritative page. Again, the random surfer model takes account of this. Why? Because an incoming link from a popular page will have more opportunities to be followed than a link from an unpopular page.
Notice that the random surfer model simultaneously incorporates both the hyperlink trick and authority trick. In other words, the quality and quantity of incoming links at each page are all taken into account.
The beauty of the random surfer trick is that, unlike the authority trick, it works perfectly well whether or not there are cycles in the hyperlinks.
This random surfer trick was described by Google’s cofounders in their now-famous 1998 conference paper, “The Anatomy of a Large-scale Hypertextual Web Search Engine.”
This article is written based on the chapter of the book called ‘Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today’s Computers‘ and all of the images here are taken from this book. If you want to learn more about algorithm, this book is highly recommended. Please check this out.
Random surfer trick is explained in details in the Google’s cofounders now-famous conference paper, “The Anatomy of a Large-scale Hypertextual Web Search Engine.”