
Xpathを使ったスクレイピングの方法
システム開発部の伊東です。ウェブネーションのコーポレートサイトに訪問していただきありがとうございます。
前回は「Rubyでクローラーを作ってみた」を書かせていただきました。今回はそのクローラーを作る上で欠かせないXpathを使ったスクレイピングについて書かせていただきます。
クローラーを知らない方は是非前回の記事を見てみてください!
スクレイピングとは?
スクレイピングとは一部の情報を抽出することです。Webサイトを例にとると、HTML文章全体から、一部のタグやテキストを抜き出す事を言います。
HTML文章のスクレイピングでは正規表現かXPathを使うことが一般的ですが、ここではXpathを使った方法を紹介していきたいと思います。
XPathとは?
XML形式の文章から、特定の部分を指定して抽出するための構文をXPathと呼びます。正確にはXML形式なのですが、HTML形式の文章もXMLの一種とみなすことができるので、スクレイピングにはとても便利なツールです。
XPathを使うメリットは?
一番のメリットは、記述が簡潔で、構造化されたHTML文章などでは取得結果の正確性が高いことです。近年では構造化されたHTML文章が主流なので、スクレイピングにはとても有用なツールです。
またChromeなどでは抽出したい要素のXPathを簡単に取得するツールがあるので、とても実践的です。
具体的な使い方
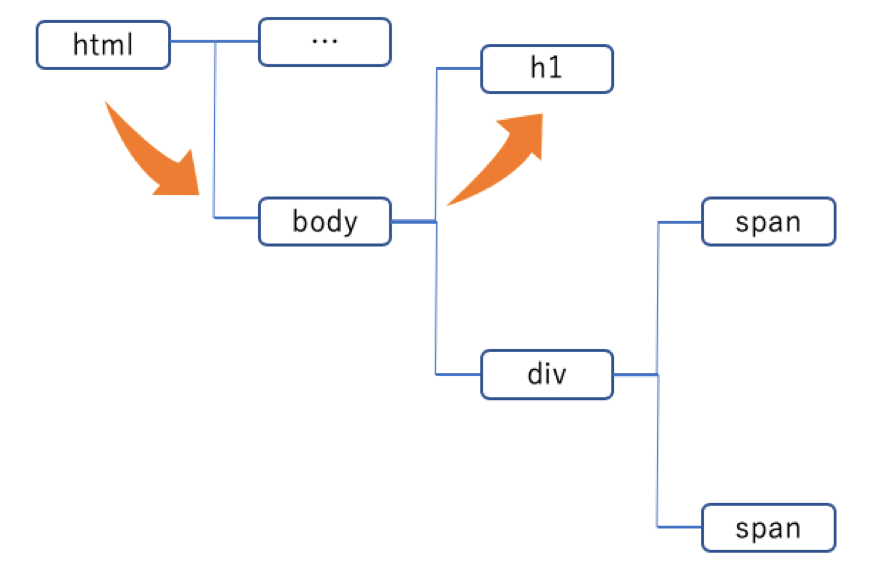
XpathではXML文章をツリーの構造として捉えることで、要素や属性を指定することができます。

例えば、このようなHTML文章の場合、下図のようなツリーの構造として考えていきます。
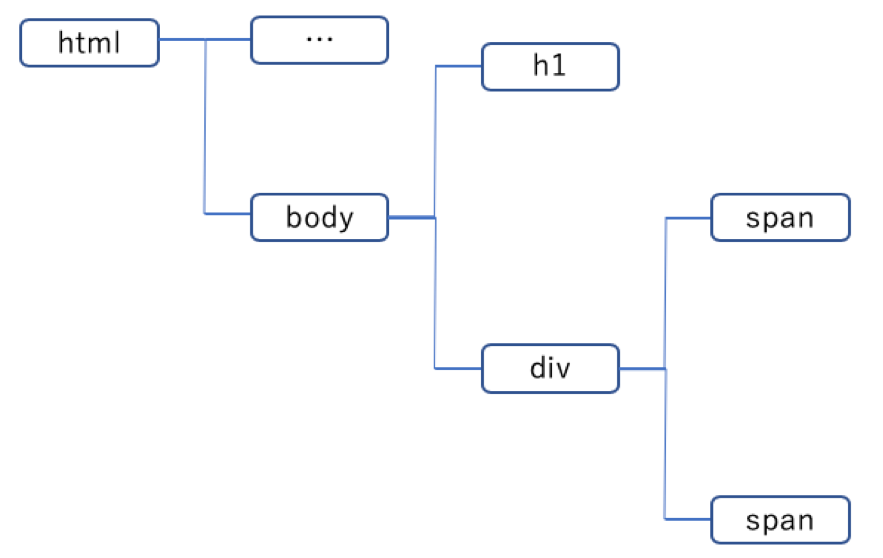
ここではh1要素を取得する方法を考えていきます。XPathはロケーションパスによって表されます。ロケーションパスとはツリー構造を「/」を使って特定の要素を指定する式のことです。
h1タグをロケーションパスで表すとこのようになります。ツリーの先頭の要素から順番に「/」を使ってh1タグまで指定していきます。
![]()
![]()
また「//」を使って途中までのパスを省略することもできます。数千行のHTML文章など、先頭からパスを指定することが困難な場合にとても有効です。ただし複数のh1タグがある場合は全て取得してしまうので、注意が必要です。
ここでは基礎的なロケーションパスのみを使った方法を紹介しました。Xpathがどんなツールなのかイメージをつかむことができたでしょうか?
ChromeでXPathを取得する方法
最後に、Chrome付属の「開発/管理」ツールでXpathを取得する方法を紹介していきます。実践的ですがとても簡単な方法なので是非利用してみてください。
実際にWebサイトをChromeで開いて試してみください!
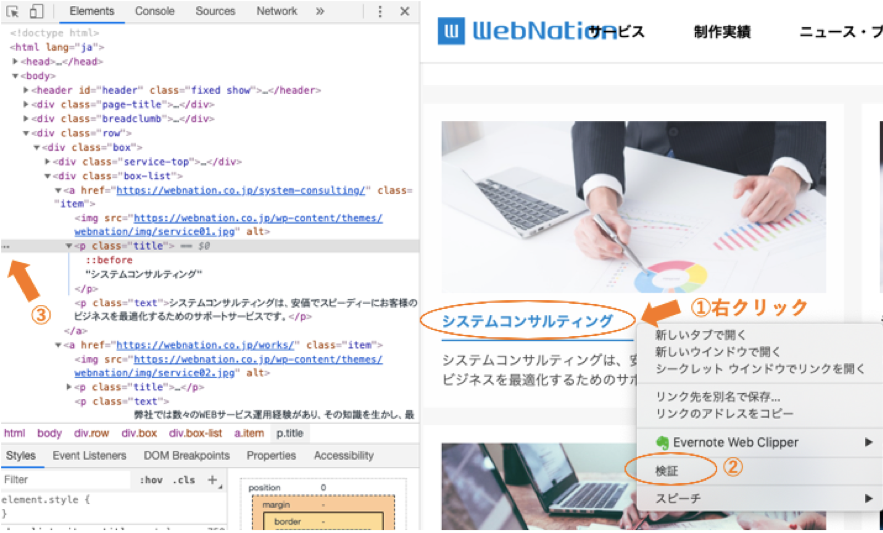
1. 取得したい要素の上にカーソルをおき、右クリックをします。
2. 「検証」ボタンを押します。
3. 取得したい要素の位置のメニューを開きます。
4. 「Copy」を選択します。
5. 「Copy Xpath」をクリックします。
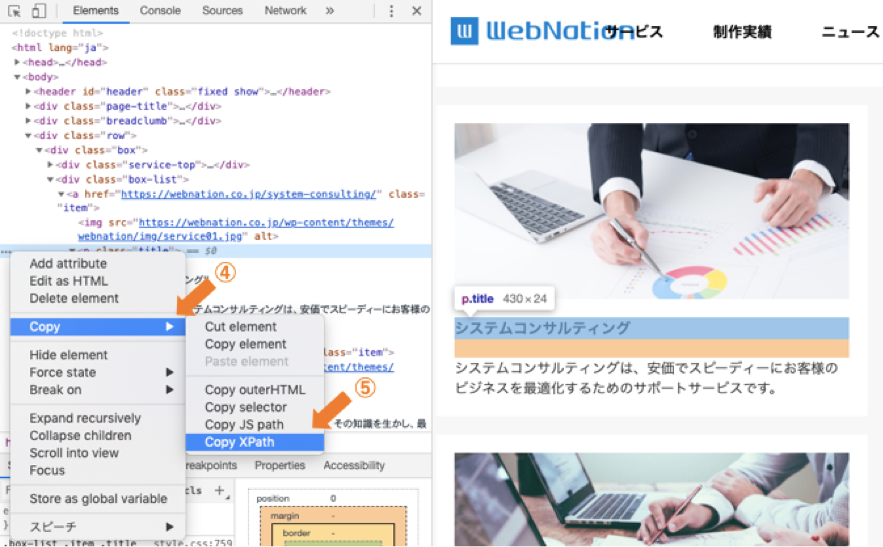
これで下記のようにXpathを取得することができました!

FirefoxでもXpathを取得するツールがあるので、Firefoxをお使いの方は調べてみてください!
まとめ
今回はXpathを使ったスクレイピングの基礎について紹介しました。XpathはChromeなどのブラウザの機能を利用することで簡単に使いこなせるようになるので、とてもオススメです。
またクラスや属性で要素を指定することもできます。正規表現を組み合わせれば、ピンポイントで要素を取得することができるので、クローラーなどを作りたい人は是非勉強してみてください!