
Scrapyを触ってみました!
こんにちは。システム開発部の京橋です。
今回は、Scrapyについての記事を書きました。
![]()
Scrapyとは
Scrapyとは、Pythonで対象のWebサイトからデータを抽出するためのフレームワークです。
今回は、scrapyを使用して「スキルタウン」の週間、月間、累計の各ランキングの上位3つのものからデータを抽出したいと思います。
Scrapyのインストールはこちらから行ってください。
実際に
まずは、Scrapyプロジェクトを作成します。
Scrapyプロジェクトを作成したいディレクトリに移動して以下のコマンドを実行します。
scrapy startproject 「プロジェクト名」
今回、「プロジェクト名」は「skilltown」で進めていくため、「プロジェクト名」を「skilltown」に置き換えます。
scrapy startproject skilltown
実行後、skilltownフォルダが作成されます。
そして、作成したskilltownフォルダに移動して以下のコマンドを実行します。
scrapy genspider 「スパイダー名」 「URL」
「スパイダー名」は「skilltown_basic」で進めていきます。「スパイダー名」は「プロジェクト名」と同じ名前を指定できないので、後ろに「_basic」を付けました。
「URL」はスクレイピングを行いたいWebサイトのURLを設定します。
今回、「スキルタウン」の出品一覧を対象とするので、「URL」は「skilltown.jp/items/search」を設定します。
「URL」は「https://」を外してください。
scrapy genspider skilltown_basic skilltown.jp/items/search
実行後、「skilltown/spiders」配下に「skilltown_basic.py」ファイルが作成されています。
このファイルに、スクレイピングするためのコードを記載していきます。
import scrapy
class SkilltownBasicSpider(scrapy.Spider):
name = 'skilltown_basic'
allowed_domains = ['skilltown.jp']
start_urls = ['http://skilltown.jp/items/search']
def parse(self, response):
pass
「start_url」は、スクレイピングする対象のURLになります。
週間、月間、累計ランキングの3ページから抽出したいので、「start_url」に3つのURLを設定します。
start_urls = [
'https://skilltown.jp/items/search?search_sort=1', # 週間ランキング
'https://skilltown.jp/items/search?search_sort=6', # 月間ランキング
'https://skilltown.jp/items/search?search_sort=7' # 累計ランキング
]
週間、月間、累計ランキングの3つのページから情報を抽出するのですが、各ページの読み込み速度が異なると出力結果の順番が思い通りにならないことがあるので、1ページごとのダウンロードする間隔(秒)を設定します。
「skilltown/skilltown/settings.py」に以下の設定がコメントアウトされているので、コメントアウトを外してください。
DOWNLOAD_DELAY = 3
次に、chromeの開発者ツールからHTML構造を確認します。
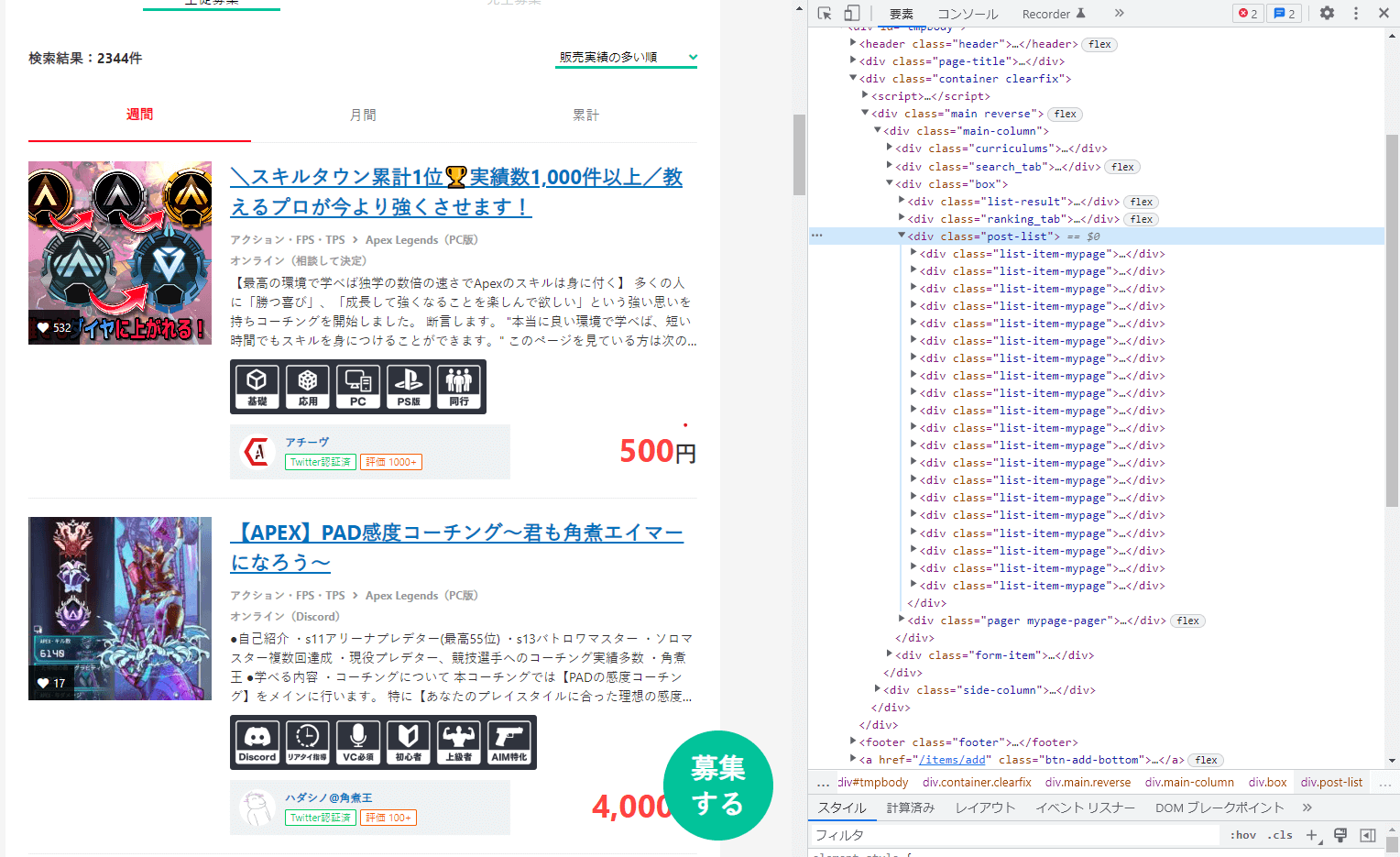
「response」に対象のWebページのHTMLが入ってくるので、CSSセレクタを使用して抽出する内容を絞っていきます。
import scrapy
class SkilltownBasicSpider(scrapy.Spider):
name = 'skilltown_basic'
allowed_domains = ['skilltown.jp']
start_urls = [
'https://skilltown.jp/items/search?search_sort=1', # 週間ランキング
'https://skilltown.jp/items/search?search_sort=6', # 月間ランキング
'https://skilltown.jp/items/search?search_sort=7' # 累計ランキング
]
def parse(self, response):
# ランキングの上位3つを抽出
# スライスが、[0:3]ではなく[2:5]なのは、スキルタウン内にある「お得なeスポーツゲームの長期コーチング」を取得させないため
products = response.css('.post-list .list-item-mypage')[2:5]
# 抽出された上位3つの出品情報を繰り返して処理を行う
for product in products:
# 出品物の詳細情報が入っているHTMLを抽出
product_texts = product.css('.item .texts')
# ユーザー名を抽出
user_name = product_texts.css('.item-bottom .user .user-data .name a::text').get()
# カテゴリーを抽出
category = product_texts.css('.category a::text')[0].get()
# サブカテゴリーを抽出
sub_category = product_texts.css('.category a::text')[1].get()
# 出品タイトルを抽出
title = product_texts.css('a.title::text').get()
# 出力
yield{
'user_name':user_name,
'category':category,
'sub_category':sub_category,
'title':title
}
実行方法は、以下のコマンドになります。
scrapy crawl 「スパイダー名」 「オプション」
CSVで出力すると、結果が確認しやすいので、オプションを設定してCSVで出力します。
scrapy crawl skilltown_basic -o output.csv
出力結果です。

流行っているApexの出品が多いことがわかりますね。
このようにスクレイピングでは、抽出結果をもとに解析を行ったり、抽出結果を加工したりなど、様々な用途で使用されます。
興味がありましたら触って見てください!