
Rubyでクローラーを作ってみた
システム開発部の伊東です。いつもウェブネーションのコーポレートサイトにご訪問いただきありがとうございます。
今までクローラーを使ったウェブサイトを制作したことはなかったのですが、今回自社のウェブサイトで制作したのでクローラーについて紹介しておきます!
そもそもクローラーとは?
クローラーとは「システムが自動的にウェブページを巡回して情報を収集するプログラム」のことです。最も皆さんに馴染みのあるものはGoogleなどではないでしょうか。
興味のあるサイトの更新情報や、最新記事の中で気になるタイトルの記事だけを取得するなどクローラーでは様々なことができます。そこで今回はクローラー作成の一連の流れを具体例を交えて紹介していきたいと思います。
また今回はRubyを使用して作成しました。普段PHPを使って開発していますが、理由としてはAnemoneやNokogiriなどクローラー向けのライブラリがRubyが充実していたことで、Ruby、HTMLの基本的な知識があれば誰でも作ることができると思います!
クローラーの作り方
どのようなクローラーでもページの「取得→解析→抽出→加工→出力」という流れで作成するのが通常となります。今回は例としてAmazon.co.jpのランキング(https://www.amazon.co.jp/gp/top-sellers/)から「本」カテゴリの「コンピュータ・IT」分野の情報を取得したいと思います!
取得
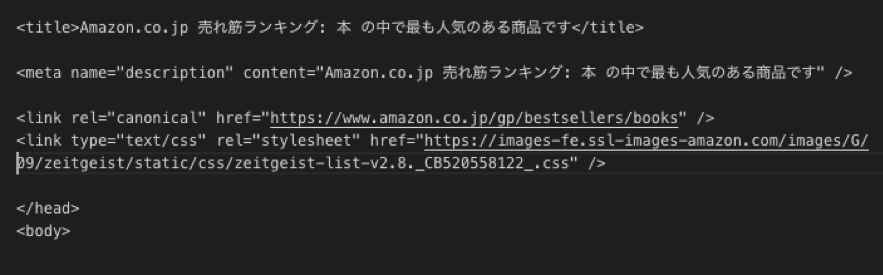
はじめに取得したいWebページのHTML文章を取得します。Anemoneというライブラリを使うと比較的簡単に取得することができます!
解析
「本」カテゴリの中には、「エンターテイメント」、「コンピュータ・IT」など20以上のカテゴリがあります。その中で特定のカテゴリのURLだけ取得します。そのためにはURLの構造を解析する必要があります。
今回は「コンピュータ・IT」というカテゴリのみを取得しました。ここでは正規表現の基本的な知識を使います。複雑なURL構造のWebサイトの場合面倒な時があります・・・
抽出
次は取得したページから目的とする情報を抜き出してみます。今回は簡単のためランキング1位の本のタイトルを取得してみます。
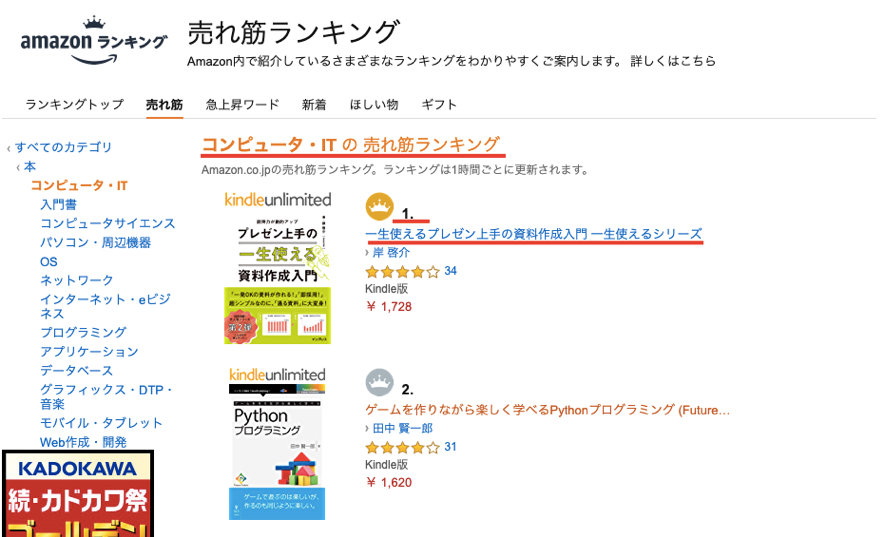
このページは次のようなHTMLの構造でした。
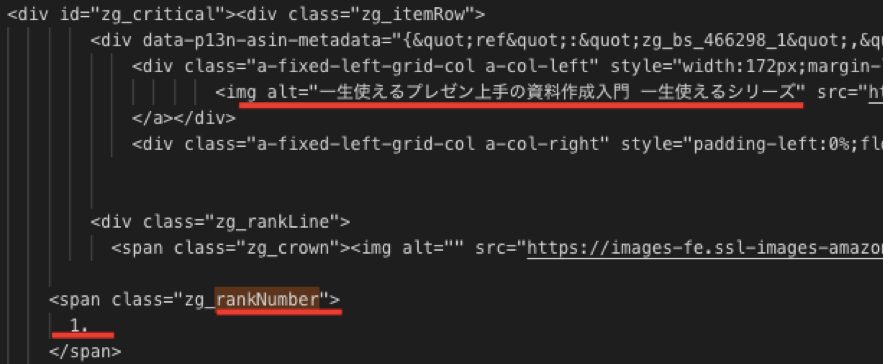
この赤線の部分をスクレイプ(抜き出し)していきます。スクレイプの方法は主に
・正規表現を利用して、パターンマッチングする
・HTMLやXMLの文法を理解して、構文解析する
の2つがあります。今回は正規表現を使用して抜き出しました。
正規表現だけはある程度理解していないとスクレイプは難しいかもしれません・・・(筆者はここで一番エラーが起きました)
加工
スクレイプするWebサイトと自分の使っている文字コードが異なる場合があります。そのときはスクレイプする文章の文字コードを変換して取得する必要があります。文字コードによっては文字化けする必要があります。
今回制作した時はほとんどサイトはUTF-8でしたが、10サイトに1つくらいの割合で異なる文字コードだったので変換が必要でした。
出力
あとはスクレイプしたデータを出力して終わりです。アマゾンランキングの1位の本のタイトルを取得することができました。

まとめ
今回は基本的な構造のクローラーを紹介しました!クローラについて少しでも理解することはできたでしょうか?
このプログラムをバッチ処理で動かせば自動的に1位の商品を一定時間ごとに取得することができます。
またさらに応用させれば、2000円以下の商品だけを取得したり、価格ドットコムのように他のサイトと比較して一番安い値段のデータだけを取得することもできます。
クローラーに興味のある方はぜひ使ってみてください!