
pgBackRestを使って簡単にPITR環境を実現しよう!
![]()
システム開発部の前野です。いつもウェブネーションのコーポレートサイトにご訪問いただきありがとうございます。
ここのところ暑い日が続きますね。なんと私がいる名古屋では本日8/3に史上初の40度超えになったとか・・・。先日浜松市にある鍾乳洞(竜ヶ岩洞)に行ってきましたが、なんと駐車場が2時間待ち・・・!
やはりみんな考えることは同じのようです・・・orz
さて、今日は珍しく日常会話は少なめに技術情報をお届けします。
pgBackRestとは?
pgBackRestとは、PostgreSQLのバックアップ&リストアツールです。別のサーバーへバックアップを保存したりするだけでなく、クラウドの代表格、AWSのS3にも保存先に対応しているのが特徴的です。
オープンソースのPostgreSQLは、少ない設定項目で高速に利用できるということもあり、弊社も含め、クラウドサービスを開発する企業の多くで使われておりますが、便利な外部ツールをあまり知られておらず、バックアップはpg_dumpしか使っていないという企業も多いのではないでしょうか?
またレンタルサーバーでよく採用されるMySQLはPostgreSQLとよく比較されがちですが、マシンスペックでチューニング設定が決まるPostgreSQLと異なり、MySQLはパフォーマンスチューニングの幅が広く、特に作るシステムの特性に合わせてチューニングが必要で、なかなか速度が出ないという同業他社様の声はよく聞きます。
MySQLでよくありがちなトラブル一例
・ランダムに結果を表示するrand関数をSQLでやってしまう。
→ SQLの見直しで改善できますが、なかなか見つけれずハマります。
・そもそもプログラムが荒く、tempテーブルを多用してて遅い
→ 荒技ですが、mysql用にtmpdirを使ってramdiskを割り当てる方法で改善できます。
・そもそもIndexを張っていない
→インフラのいない会社でほぼ100%の確率でやっているので、ご案件を受ける場合、ここをまずチェックしています。
・・・そのため、弊社ではパフォーマンスチューニングの学習コストが少ないPostgreSQLを使ったシステムを多くで採用している背景がありますが、PostgreSQLは大規模システムになればなるほど情報量が少ないため、PITRや複数台構成となるとハードルを高く感じるのではないでしょうか?
実際私もそうでしたが、とあるシステムでタイムリーにPITRの要件が出たので使ってみたらめっちゃ便利だったというお話で、是非ともPostgreSQL環境でお悩みのインフラエンジニアにオススメしたいソフトウェアを紹介します。
PITRとは?
冒頭に触れたように、pgBackRestとはPostgreSQLのバックアップ&リストアツールですが、同時に簡単にPITRを実現できるツールでもあり、トランザクションのアーカイブログ(WAL)を参照してリカバリーを実現する手法です。
メリットとしては
・PostgreSQL8からPITRは機能として実装されており、今まで使っていたシステムでも利用できる
・バックアップスクリプトを使わずに、最新状態までリカバリーできる
・PITR(ポイント・イン・タイム・リカバリー)という名称にあるように、好きな時間に遡ることができる
という反面、デメリットとしては、
・WALの管理が大変
・WALの管理を放置しているとバックアップ先の容量に注意する必要がある
という特徴があります。
実際のところ、ベースバックアップを取り、その差分(WAL)のバックアップを取り続ける必要がありますので、どこまでを削除して良いかは判断が難しいです。かと言っても不完全な状態でWALを消してしまうと、途中でバックアップから復元ができなくなってしまいます。
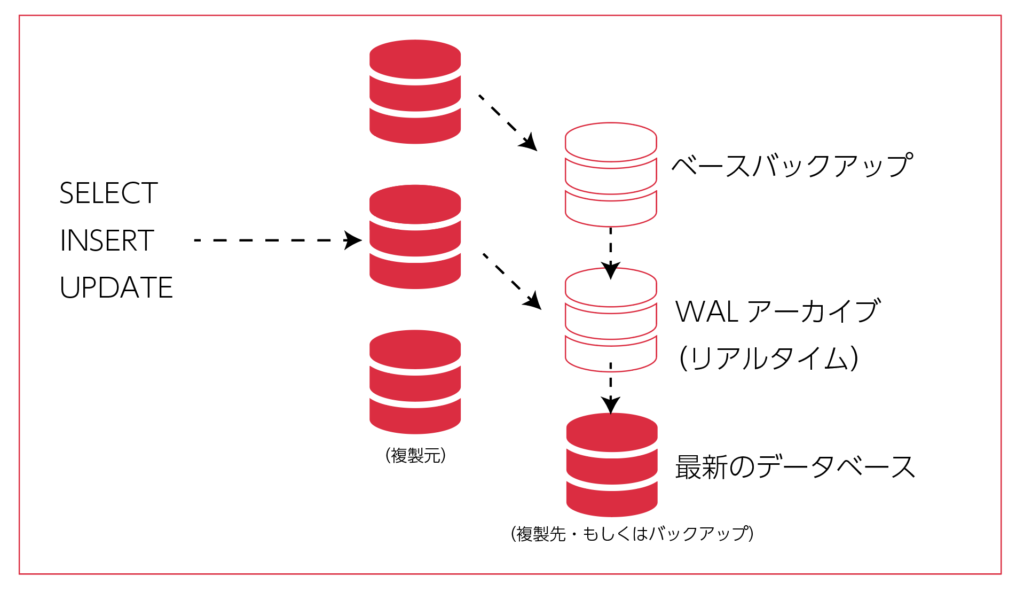
そこでWALの管理を簡単にしつつ、まとめてバックアップとリストアまでオールインワンで解決してくれるのが、このツールの便利なところです。
また導入するのにPostgreSQLの再コンパイル不要という点も私が採用するのにもっと惹かれた理由です。導入するのにDBを再コンパイルしてバージョンが変わってしまうのも問題ですし、もっとも今まで安定していたのが急に不安定になったら意味がないですから・・・。
他にも国産ツールで、pg_rman(github)という同様のことを実現できるツールも公開されていますが、使っていたDB環境(PostgreSQL8.4)は非対応だったため、他のツールを渡り歩き、結果的にpgBackRestに巡り合ったという経緯があります。
現時点でPostgreSQLはバージョン11がリリースされており、8.4は既に開発元でサポートが終了したEOL状態ですが、長期サポートで有名なCentOS6/RHEL6系で標準リポジトリに入っているため、まだ使われている企業も多いのではないでしょうか。
pgBackRest環境を作ってみる
前置きが長くなりましたが、今回は稼働機/予備機のアクティブスタンバイ構成を作ってみようかと思います。
(稼働機側)
/var/lib/pgsql postgresqlフォルダ
/var/lib/pgsql/data postgresql DBフォルダ
/var/lib/pgsql/wal_spool WALアーカイブ先(一次フォルダ)
/var/lib/pgsql/wal_backup WALアーカイブ先(NFSマウント先:二次フォルダ)
(予備機側)
/var/lib/pgsql postgresqlフォルダ
/var/lib/pgsql/data postgresql DBフォルダ
/var/lib/pgsql/wal_spool WALアーカイブ先(一次フォルダ)
/var/lib/pgsql/wal_backup WALアーカイブ先(NFSマウント先:二次フォルダ)
上記環境にて、NFSフォルダは別サーバーのフォルダをマウントするという想定で進め、NFSサーバーの構築は割愛します。
# PostgreSQLのインストール(稼働機&予備機)
yum -y install postgresql-server
# pgBackRest前提ソフトウェアのインストール(稼働機&予備機)
yum -y install zlib-devel postgresql-libs postgresql-devel pam-devel readline-devel openssl-devel perl-devel perl-ExtUtils-Embed perl-Time-HiRes perl-JSON perl-Digest-SHA perl-Digest-SHA1 perl-parent perl-DBD-Pg perl-XML-LibXML perl-IO-Socket-SSL
# WALアーカイブ保存先の準備(稼働機・予備機)
mkdir -p /var/lib/pgsql/wal_spool
mkdir -p /var/lib/pgsql/wal_backup
chown postgres:postgres /var/lib/pgsql/wal_spool
chown postgres:postgres /var/lib/pgsql/wal_backup
# WALアーカイブ保存先としてNFSフォルダのマウント
mount /var/lib/pgsql/wal_backup
これでPostgreSQLのインストールとNASのマウントが完了しましたので、いよいよpgBackRestの環境構築を進めていきます。
# pgBackRestのインストール(稼働機・予備機)
mkdir -p /var/lib/pgsql/src/
cd /var/lib/pgsql/src
wget https://github.com/pgbackrest/pgbackrest/archive/release/2.04.tar.gz
tar -xvzf 2.04.tar.gz
cd /var/lib/pgsql/src/pgbackrest-release-2.04/src
make
make install
# pgBackRestの動作確認(稼働機・予備機)
pgbackrest version
# pgBackRestのログフォルダの設定(稼働機・予備機)
mkdir -p /var/log/pgbackrest
chown postgres:postgres /var/log/pgbackrest
# pgBackRestの設定(稼働機)
vi /etc/pgbackrest.conf
[sample]
pg1-path=/var/lib/pgsql/data
[global]
archive-async=y
archive-push-queue-max=8GB
spool-path=/var/lib/pgsql/wal_spool
repo1-path=/var/lib/pgsql/wal_backup
repo1-retention-full=5
start-fast=y
process-max=4
[global:archive-push]
compress-level=3
(上記の説明)
async(非同期)モード WALアーカイブをプッシュするためのフォルダを指定
spool-path 一次フォルダ(マニュアルでもローカルディスク推奨)
repo1-path 二次フォルダ(NFS or Amazon S3)
retention-full 5世代まで保存
start-fast WALを強制的にアーカイブ
process-max 同時に4スレッドまで動作(ご利用環境のCPUに合わせてください)
# pgBackRestの設定(予備機)
vi /etc/pgbackrest.conf
[sample]
pg1-path=/var/lib/pgsql/data
[global]
repo-path=/var/lib/pgsql/wal_backup
pgBackRest環境で遊んでみる(バックアップ実行編)
インストール直後はPostgreSQLが初期化されていないため、まずは初期化します。
# PostgreSQLの初期化
service postgresql initdb
初期化すると/var/lib/pgsql/dataフォルダが作成されますので、pgBackRestを使う項目を設定します。
最低限設定すべきことは「アーカイブモードの有効化」「アーカイブ時にpgbackrestを起動する」だけです。
# PostgreSQLでアーカイブモードを有効にする
vi /var/lib/pgsql/data/postgresql.conf
archive_mode = on
archive_command = 'pgbackrest --stanza=sample archive-push %p'
# PostgreSQLの起動
service postgresql start
これで準備は完了です。それではバックアップカタログを初期化し、pgBackRestを利用できるようにしましょう。
#バックアップカタログを初期化
pgbackrest --stanza=sample --log-level-console=info stanza-create
INFO: stanza-create command begin 2.04: --log-level-console=info --pg1-path=/var/lib/pgsql/data --repo1-path=/var/lib/pgsql/wal_backup --stanza=sample
INFO: stanza-create command end: completed successfully
ここでは「sample」という名称でバックアップカタログ(stanza)を作成します。
# バックアップカタログのチェック、およびWALバックアップのチェック
pgbackrest --stanza=sample --log-level-console=info check
「sample」という名称でバックアップカタログ(stanza)が正しく作成されたかどうかチェックします。
# バックアップ実施、初回はフルバックアップ
pgbackrest --stanza=sample --log-level-console=info backup
さらっと一行で書いていますが、実はこれが本番で、バックアップカタログ「sample」でバックアップを実施しています。
初回はデータがありませんので、フルバックアップを実行していますが、裏ではベースバックアップの作成と、バックアップデータが完了した後、バックアップ開始から終了までの差分(WAL)をバックアップカタログへ反映しています。
# バックアップステータス確認
pgbackrest --stanza=sample --log-level-console=info info
最後にステータスを確認し、以下のように正しくバックアップが完了したかを確認します。
stanza: sample
status: ok
db (current)
wal archive min/max (8.4-1): 000000010000000900000077 / 000000010000001F0000007B
full backup: 20180803-061001F
timestamp start/stop: 2018-08-03 06:10:01 / 2018-08-03 06:11:45
wal start/stop: 000000010000001C0000009C / 000000010000001C0000009D
database size: 7.6GB, backup size: 7.6GB
repository size: 1.9GB, repository backup size: 1.9GB
正しくバックアップが確認できましたら、後はCronでバックアップコマンドを定期実行するだけです。もう面倒なWALの管理の心配もいりません。
pgBackRest環境で遊んでみる(バックアップ復元編)
今までの流れで、バックアップがNASに保存されているのが確認できましたので、今度は予備機からバックアップを復元したいと思います。
(復元の際の注意点)
・予備機で稼働機のバックアップが参照できていること
・予備機でPostgreSQLが起動していないこと
# バックアップカタログから復元(予備機で実施)
pgbackrest --stanza=sample --log-level-console=info --delta restore
service postgresql start
今回もさらっと書いていますが、たったこれだけです。
設定ファイルで指定されたパス/var/lib/pgsql/data以下を削除しますので、予備機にあるデータは全て上書きされますので、ご注意ください。
自動的にrecovery.confが生成され、PostgreSQL起動時に復元時にすべき情報も自動設定されていますが、postgresql.confの記述が稼働機と同じになっていますので、このまま起動すると、バックアップ前のアーカイブが上書きされてしまう恐れがあります。
PostgreSQLを起動する前に、アーカイブを別フォルダに退避したり、予備機ではアーカイブモードを無効にしたりするなど工夫は行なっても良いかもしれません。
また稼働機と予備機でスペックが異なるため、パフォーマンスチューニングのパラメーターも稼働機仕様にしたくない場合は個別にご対応ください。