

StableDiffusionでちびきゃらを生成してみよう+おすすめLoRA
みなさんこにちは、ウェブネーションの山下です。
StableDiffusionでの画像生成を始めて一年ほどたちまして社内でちびキャラを生成する需要がわりとありましたので、モデル・プロンプトとおすすめのLoRAなどご紹介します。
モデル
aicekawaice
https://civitai.com/models/51057/aice-or-kawaice
軽量でちびキャラ生成にはマッチしたモデルかと思います。
プロンプト
Prompt
best quality, 1 girl, solo, chibi, full body, standing, white background, redNegativePrompt
(worst quality, low quality:1.4)とくに特別なプロンプトはありません「chibi」を入れるとちびキャラとして生成されます。
生成
以下の設定で生成してみます。
| Sampling method | DPM++ 2M Karras |
| Sampling steps | 20 |
| Width | 512 |
| Height | 512 |
| CFG Scale | 7 |
ちびキャラだから生成が早いのでしょうか?社内のRTX3060搭載のPCでも100枚の生成が7分ほどで完了しました。
生成結果

ちびきゃらにおすすめのLoRA
表情系のLoRAをいくつか試してみます。
十条蛍(Hotaru Jujo)様の作成したLoRAを使わせていただきます。
https://huggingface.co/JujoHotaru/lora
生成した画像群から1枚画像を使いたいので、画面内の「PNG Info」タブから画像をアップロードします。
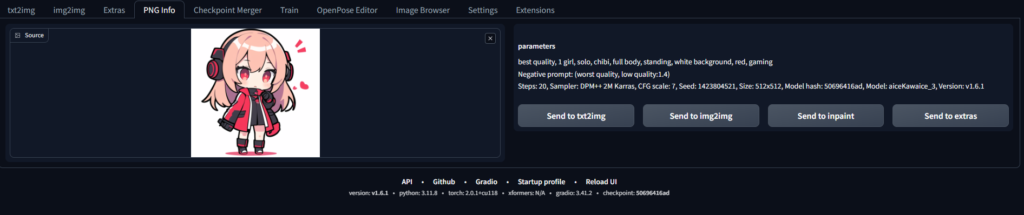
アップロード後右側の「Send to img2img」をクリックしてimg2imgの画面へ画像情報を読み込みます。
配布元から拡張子「safetensors」のファイルをダウンロード後「\steable-diffusion-web-ui\models\Lora」へファイルを配置します。
するとimg2imgのLoraタブ内にLoRAが読み込まれるのでクリックしてプロンプトに追記させます。
それではいくつか生成してみます。
元画像
適応後



いい感じに表情が変更されているのではないでしょうか。
「ジト目」「白目」「><」などの表情が数秒で生成されます。
img2imgだと髪型や服装が微妙に変わってしまうので表情差分に使うには顔だけPhotoShopで張り付けたり、「Inpaint」等を使った部分認識を適応させる必要があります。
ご覧いただきありがとうございます。
以上、StableDiffusionでちびきゃらを生成する流れでした。