
先日発生したEC2の障害で学ぶ耐障害性の高い構成
こんにちはシステム開発部の前野です。今日は久々にインフラのお話です。
先々週の金曜日夜(2/19 23時頃)に発生した大規模障害では、サービスの影響を受けたところも多かったのではないでしょうか?
弊社のシステムでも多くのアラートが飛んできたり、個人的に使っているサービスではうっかりマルチAZ構成をし忘れていて、アラートに気付いた時にはやっちまったぜ・・・と、
AWSのHealth Dashboardを呆然と見るしかなかった物もありましたが。。。
さて、まずはどんな事があったかおさらいしてみましょう。
原因は冷却設備の故障

原因は東京リージョンのデータセンターのうち、ap-northeast-1cの冷却に問題があり、サーバが過熱し、広範囲の障害に至ったとされています。
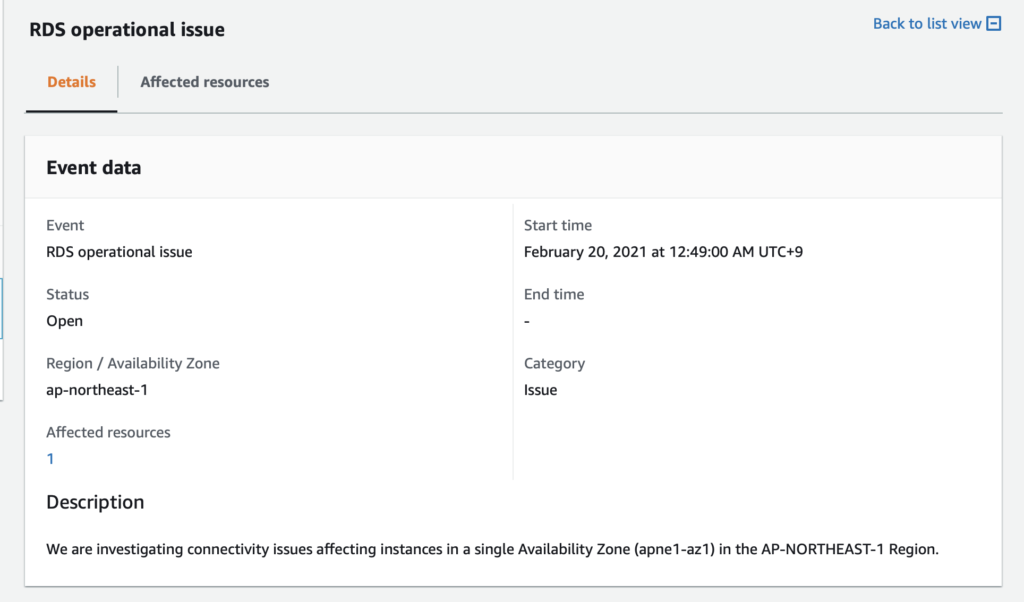
その結果23時前後でEC2がまずダウンしログインができなくなる事象がありました。EC2に繋がらないので、当初気付きませんでしたが、土曜日に日付が変わってからRDSでも障害発生の報告が確認されました。
今回の問題は単一のAZでのみ発生
今回起きた問題はap-northeast-1cのみで、他のAZでは発生していないため、その後RDSでは自動バックアップが有効ならPITRで別サーバーを立ち上げ、他AZへ移動するようにというアナウンスもありました。
時間は多少前後しますが、25時頃にはEC2には繋がるようになったと思います。ただ、RDSの復旧は30時頃までずれ込んだようでした。
過去にはこんな障害も
このような障害は2-3年前にも起きており、今回のような影響が長期化した障害がありました。
私はちょうど実家への帰省から自宅に戻る途中で、障害の発生は鳥取砂丘の近くにある魚市場で昼ごはんを食べていて気付いたのですが、
Yahooリアルタイムでツイートを見るとエンジニアの地獄絵図が思い浮かぶようなツイートが多く出てきたと記憶しています。
https://aws.amazon.com/jp/message/56489/
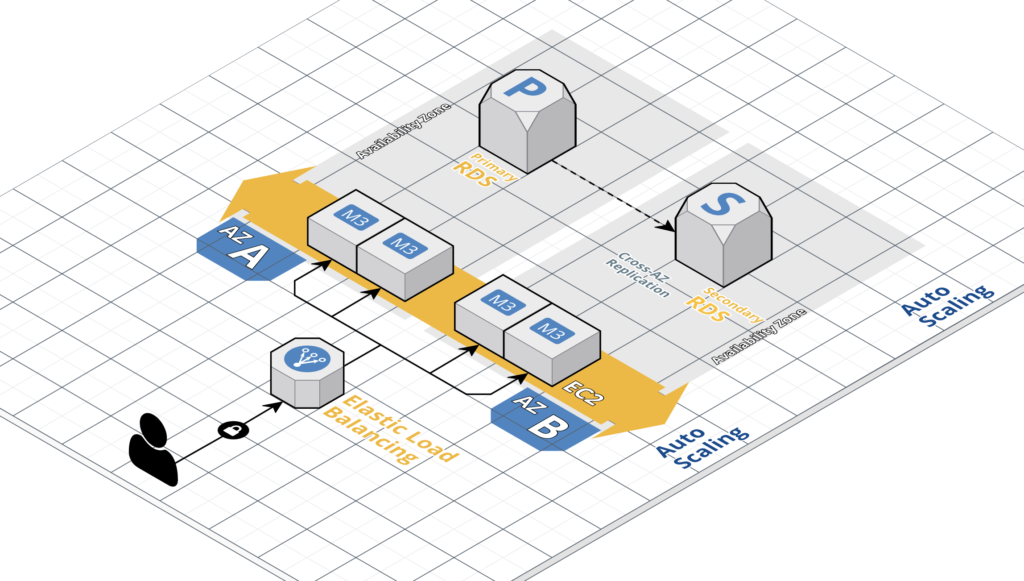
当時はたまたま影響するサービスがなく特に対応することはありませんでしたが、今回のようにサービスが広がれば影響を受ける確率も増えるので、今後はマルチAZ構成を標準にしようかと思います。
障害を受けたサービスはマルチAZ構成に向けて準備中
さて、そんな個人的に使っているサービスではEC2 + RDS + EFS + API Gateway + Lambda + DynamoDBで構成されていますが、
EFS、API Gateway、DynamoDBは元々冗長化されたマネージドサービスにおいては、障害の影響を受けることはありませんでした。
ただ、直撃を受けた問題のEC2とRDSはマルチAZになっておらず、両方共にap-northeast-1cに格納されているため今回影響を受けてしまい、
RDSは復旧作業の過程でマルチAZ構成にし、1c/1dにて元気に稼働中です。
クライアント案件のサービスは基本マルチAZ構成だったため、今回の障害においてRDSでは自動的にフェイルオーバーがかかり、停止影響は数秒でしたので、次回同様の障害ではお守りをする必要はなさそうです。
問題はウェブ側のEC2のみを残す状態となり、ELBでSSLを終端し、オートスケールグループに入れて昔ながらの構成で負荷分散をさせるか、
最近流行りのコンテナ化にして構成を自動化にさせようかと考えているところです。
先週はこのAWSの障害をずっとウォッチしていたら徹夜をしてしまい、体調を崩してしまったので、今週の週末にゆっくり畑仕事をしながら進めようかと思います。